

這次的分享主要是針對入門的文本分析步驟,雖然沒有太多技術細節,但至少可以讓沒有接觸過這一塊的人了解可能的作法與需要的工具
資料分析可以簡單的分為三大步驟:
- 收集資料
- 過濾資料
- 顯示資料
收集資料
爬蟲(Crawling)是一種收集資料的手段,針對網站可以分析 html 架構之後再透過相關 http client 的 library 撰寫程式取得資料,像是 python 的 requests 與 BeautifulSoup 的搭配使用
另外如果該網站或是該服務有提供 API,那我們只要透過 API 做 request 就可以拿到整理好的資料(通常格式都會是 csv,xml,json 其中一種)
過濾資料
拿完資料之後,不論是結構式資料或是非結構式資料,原始資料內都會有許多不會影響到你的決策但卻會干擾分析的資料,我們稱之為噪音(noise)
一開始很難得知哪些資料是噪音,因此必須透過一些指標來整理並判斷過濾資料,而這些步驟會不斷重複,直到你覺得資料已經出現趨勢時就可以停止
顯示資料
也就是所謂的資料視覺化(Data Visualization),針對你想呈現的訊息,研究怎樣的呈現方式可以讓人一目了然
這邊想特別提到一篇最近看到的文章:信息圖表是如何煉成的(一):圓形與線條 | 海外學習筆記。雖然說文章中提到的視覺化程度可以算是尾聲的階段,但是這種可以很直觀傳遞資料意涵的圖表的確是所有資料科學家可以努力的方向
前面資料分析的階段很重要,但是視覺化的這部份也需要花時間好好研究,就像網站設計如果 UI/UX 不好,我覺得會讓事前準備的那些工作全都事半功倍
目標
接下來要分享的這些流程是我從毫無經驗的狀態,花了大約兩個禮拜做的東西,因此覺得這對於完全沒有學過資料分析的人,門檻應該算是相對來的低,但是同樣的這些也只是很初步的分析
這篇文章的目標是「分析 Facebook 粉絲團貼文內容與按讚數,分享數之間的關聯性」,對於需要做網路行銷,社群行銷的人,可能幫的上一點忙,在購買 Facebook 廣告之餘,了解你的目標族群喜好的關鍵字與內容
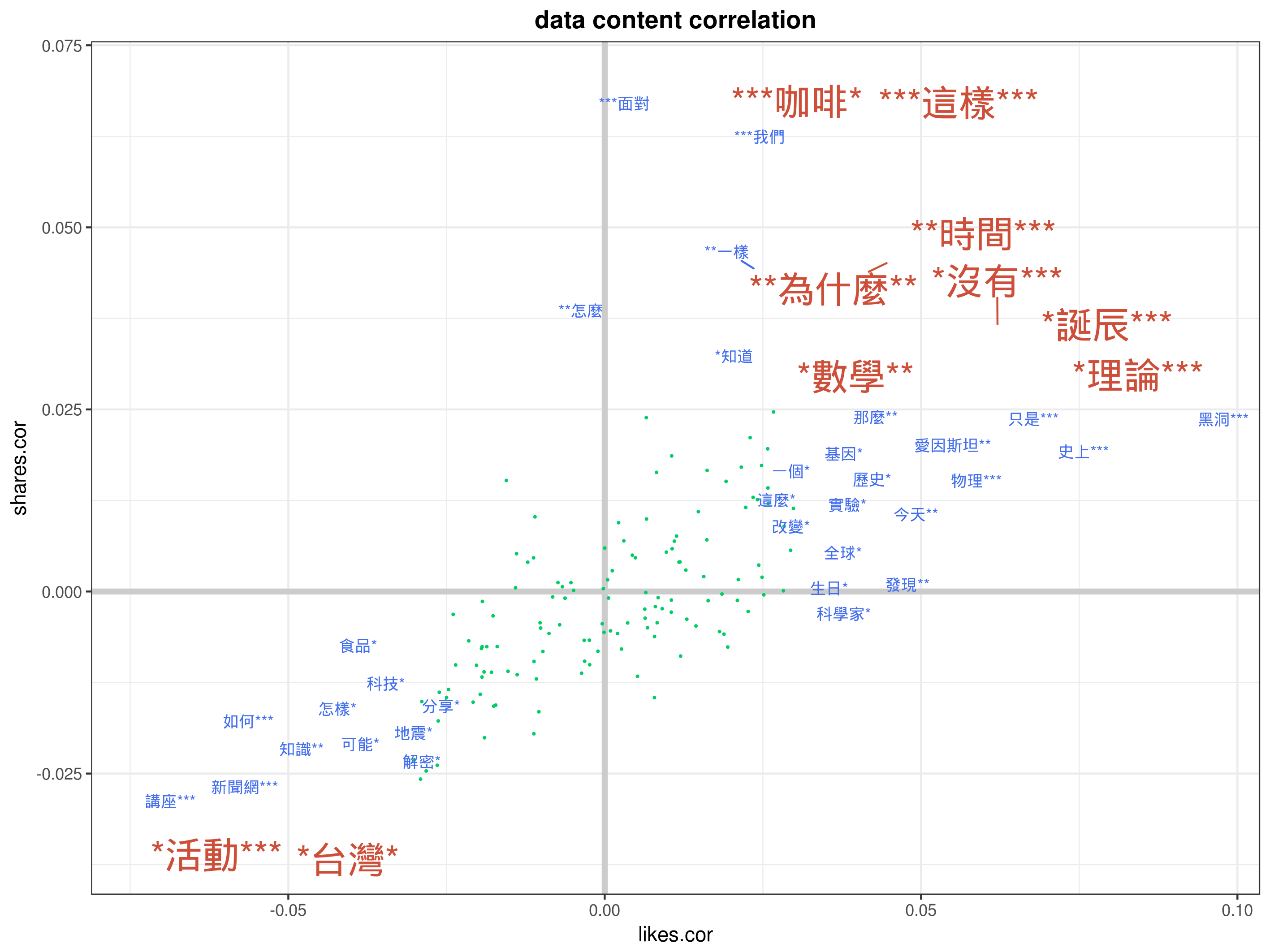
初步期待的結果是最後可以得到以下這種圖表
收集資料
目標是讓新手可以快速取得一些資料並開始著手進行分析,因此在收集資料這塊,打算用比較簡單的方式
取得 Facebook 資料除了可以透過分析網頁然後做爬蟲(較難的方式)以外,還可以透過 Facebook 所提供的 Graph API 取得,相關的 API 文件可以去官網查詢,而我這次要使用的是透過 Python 的 requests library 搭配 Facebook URL API,取得文章內容,按讚數量,以及分享數量
在官網上你可以看到他有列出一些 SDK(Software Development Kit),這邊只是提供其他管道做爬蟲,但是跟我接下來的內容沒有甚麼直接關係
Facebook 爬蟲要做的第一件事情就是要取得 Access token,這個在 Graph API 中就可以取得,直接複製貼上到我們的程式之中使用即可,但是在這邊需要提醒一件事情,那就是 Access token 有效期限,某些 application 在使用之前會要求 Facebook login,這就是為了取得有效的 Access token。如果未來你要用同一份程式碼爬蟲,記得要更新 Access token,更詳細的 Token 可以參考官網文件
Native mobile apps using Facebook's SDKs will get long-lived access tokens, good for about 60 days.
Access tokens on the web often have a lifetime of about two hours
雖然還是有方法可以延長 Access token 有效期限,甚至可以取得永久 Access token,但我個人覺得不太安全也沒有必要
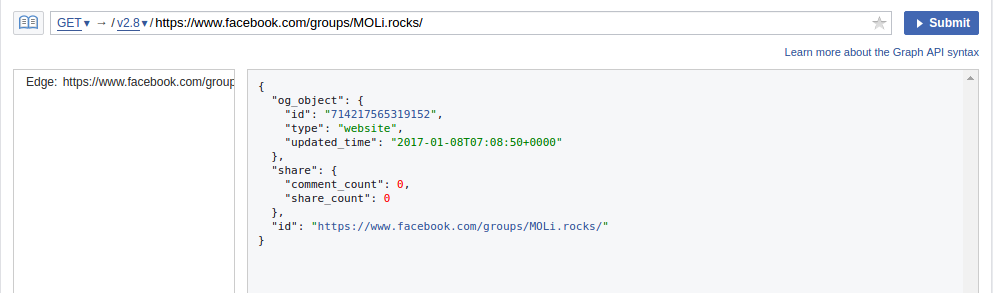
回到正題,Facebook 爬蟲要做的第二件事情是要取得你想要分析的粉絲團 id,同樣的,這件事情可以透過 Graph API 取得,這邊以 Moli 社團為例,進入臉書頁面之後將上面的網址複製貼到 Graph API 上,submit 之後你可以透過回傳物件看到 id
import requests
import json
token = '...'
id = '...'
# 透過 python request 接 facebook URL API 拿到我們所需要的資料
all_post = requests.get('https://graph.facebook.com/v2.8/{id}?fields=posts.limit(100){{id,created_time,name,likes.limit(0).summary(true),shares,message}}&access_token={token}'.format(id=id, token=token))
# 透過 python json 將 response 轉為 json 物件
all_post = all_post.json()
透過上面的程式碼我們會拿到以下這種格式的回傳物件
{
"id": "...", # 你要搜尋的粉絲團或是社團 id
"posts": {
# 因為 facebook API 會限制單次回傳的文章數量
# 所以要透過不斷的 request "paging" 中的 "next" 取得其他文章
"paging": {
"next": "...",
"previous": "..."
}
"data": [
"id": "...", # 文章 id
"message": "...", # 臉書貼文文章
"name": "...", # 外部連結標題
"created_time": "...",
"shares": {"count": ...},
# 這邊我們只需要 "total_count",所以可以在爬蟲之後重新修改一下 json 結構
"likes": {
"data": [],
"can_like": ...,
"has_like": ...,
"total_count": ...
}, ...
]
}
}
這邊提供幾個對 python 比較不熟的初學者,可能會用到的 Tips
# 想要在 terminal 上看有階層式的資料(e.g. json, dict)
from pprint import pprint
pprint(all_posts)
# 過濾臉書發文的時間(e.g. 我只想分析近兩年的文章趨勢)
# facebook time stamp format example: "2015-04-10T08:40:00+0000"
# 轉成 datetime 物件再去做處理會比較恰當
from datetime import datetime
dt = datetime.strptime("2015-04-10T08:40:00+0000", '%Y-%m-%dT%H:%M:%S+0000')
dt.year # output: 2015
# 透過文章 id 過濾重複文章
list({ i['id']:i for i in all_posts['posts']['data'] }.values())
# 將處理完的資料存成 json
# 透過 `with` 會在文件操作結束之後自動幫你 file close
# 如果你需要直接看 json file,可以在 json.dump 加上 indent,但是檔案容量會比較大
# 所以如果要餵給其他檔案做讀取時,建議不要使用
import json
with open('data.json', 'w+') as f:
json.dump(all_posts, f, indent=2)
過濾資料
從這邊開始會一邊說明基本過濾資料流程,一邊透過 R 來說明實作部份的程式碼,但不包含太多 R 的基本操作
利用 R 來做 Text mining 之前,我們需要先對我們要分析的標題或是內文做斷詞,而目前比較多人用來做中文斷詞的是 jieba(python R)。而斷詞的準確率會直接影響到後面做的分析,所以這邊我會先說明幾項斷詞需要注意的事項
字典
字典的功能就是所謂的查表,我要讓程式知道哪些文字組合在一起是一個單字,這邊其實 jieba 本身就有字典檔,但對於繁體中文字的處理其實並沒有很好,所以這邊可以去網路上找一些繁體中文字的字典檔。打開字典檔你會發現有許多筆語料資料,語料資料同常會包含單字,權重,詞性等,所以其實你也可以自己定義字典檔
停止詞 stop words
所謂的停止詞就是一些對文章沒有實質上的影響,頻率卻很高的字,像是「首先」「非常」或是一些連接詞。由於我們要做的是尋找關鍵字,所以停止字也是我們要過濾的噪音之一,而這個其實可以在斷字的時候就將其排除,同樣的,這邊也是可以自己定義哪些屬於停止詞,但是這邊可以很簡單存成 csv 就可以了
1. 讀檔
我們在上面用 python 蒐集完資料之後存成 json 檔,現在我們要用 R 讀進剛剛的 json 檔
install.packages(rjson, dependency = T)
library(rjson)
json_data <- fromJSON(file = "data.json", method = "C")
備註
安裝 packages 的時候你可以直接打 install.packages(rjson),也可以打 install.packages("rjson"),雖然看起來沒甚麼不同,但這算是蠻進階的 R Tips,這個我覺得蠻有趣的可以研究一下 NSE(Non-standard evaluation)
NSE is particularly useful for functions when doing interactive data analysis because it can dramatically reduce the amount of typing
2. 斷字
首先我們要先引入 jiebaR,這邊安裝的的方法都一樣,然後要宣告一個 worker,你可以把他想成斷字器,在這邊我們可以使用自己定義的字典檔
install.packages(jiebaR, dependency = T)
library(jiebaR)
cutter <- worker(user = "user.dict.new.txt")
接著我們要注意一件事情,那就是剛剛透過 R 讀進來的 json 檔案格式,在 R 裏面並沒有 json 這種資料格式,取而代之的是利用 list of list 的方式儲存
R 眾所皆知的是適合拿來做矩陣運算,向量運算等等的程式語言,做 for loop 這種操作反而很沒有效率,所以通常大家會使用 apply,lapply 等等的方式取代 for,在這邊其實還可以透過平行運算加速,也就是我們接下來要安裝的 parallel。我們可以利用 parallel library 中的 mclapply 來讓斷字的過程加速
install.packages(parallel, dependency = T)
library(parallel)
# define as function
# 這邊針對標題(name)做範例介紹斷字流程,並使用自定義停止詞將其排除
stopwords <- read.csv(file = "stopwords.csv", header = F)$V1
break.file <- function (f) {
mclapply(1:length(f), function (x) {
if ("name" %in% names(f[[x]])) {
# 1. 這邊我不會讓斷字結果把原本的標題取代掉,這樣後面要看關鍵字範例會比較方便
f[[x]]$raw_name <- f[[x]]$name
# 2. 斷字 > 過濾 stopwrods > 過濾英文數字 > 過濾空白
segment.words <- segment(f[[x]]$name, cutter)
segment.words <- filter_segment(segment.words, stopwords)
segment.words <- gsub("[0-9A-z]+?", "", segment.words)
segment.words <- str_trim(segment.words)
segment.words <- segment.words[segment.words != ""]
f[[x]]$name <- segment.words
}
f[[x]]
})
}
3. 頻率篩選
接著要進入主要的分析流程,我們要從剛剛所有文本的斷字結果中找出關鍵字,而這並不是單單看出現頻率的高低就可以直接宣稱該單字是關鍵字。可能有字典以外的 stopwords 沒有被過濾掉,或是斷字結果不夠正確的都還是有可能成為資料雜訊,這邊可能就要等最後結果出來之後回頭找文本範例檢查是否真的是關鍵字來判斷
雖然說出現頻率無法直接等於關鍵字,但卻也是其中一項指標,因此我們可以先把剛剛出現的斷字結果拿去計算出現的次數,在 R 裏面可以使用內建函數 freq 簡單的得到結果,接著我們必須思考出現頻率與關鍵字之間的關係,假如說「科學」這個關鍵字幾乎在每篇文章都有出現,他是屬於對讀者有吸引力的關鍵字?或是根本沒有影響力?
以我這次做的分析為例,我認為出現頻率太極端的單字都可以排除在分析以外,出現頻率超過 70% 以上或是低於 1% 以下的單字我都不納入後面的分析流程(這邊只是舉例)
4. 權重
當我們根據頻率篩選完之後,會得到一個比原本斷字結果還要小的單字集合,但是這邊每個單字的權重是否都一樣呢?
回頭思考,我們上一步驟是根據頻率篩選,但這樣結果有可能是某一個單字在其中一篇文章出現頻率超高,但出現該單字的文章數卻很少,考慮到這一個狀況,我一開始的作法是建立一張表格,計算該單字是否有出現在文章內,並列出該文章相對應的按讚與分享數
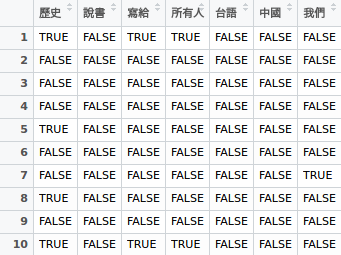
但是後來被建議可以使用 TF-IDF,這個用於 text mining 的加權技術會同時考慮到出現的文章篇數與出現在同一篇文章內的次數,因此我這個分析後來就用 TF-IDF 重做了
5. 關聯性分析(Correlation & p-value)
當我們做完頻率的初步篩選以及單字的權重之後,我們接著就要做這些單字跟按讚數以及分享數之間的關聯連性分析,雖然是統計領域,但這些觀念其實國高中應該都有說過
e.g. 當變數 A 的值越來越大時,變數 B 的值也越來越大時我們稱變數 A 與 B 是正相關,反之變數 B 的值越來越小時我們稱變數 A 與 B 是負相關
透過上面的例子來,我可以可以把剛剛得到的「單字在文章中的 TF-IDF value」視做變數 A,而按讚數或是分享數視做變數 B,然後透過 R 內建函數 cor.test 得到兩個變數之間的關聯性,如果自己做測試你會看到類似下面這種格式的東西
cor.test(x, y,)
Pearson's product-moment correlation
data: x and y
t = 1.8411, df = 7, p-value = 0.05409
alternative hypothesis: true correlation is greater than 0
95 percent confidence interval:
-0.02223023 1.00000000
sample estimates:
cor
0.5711816
這邊我們需要的是 cor 與 p.value 這兩個值,在統計學中 p-value 經常被拿來視做統計果的顯著性,剛好最近有些文章在探討,建議有興趣的人可以仔細看一下,這些包含了 p-value 的本質以及虛無假設的相關探討,我會放在後面 reference
雖然說 p-value 有些討論空間,但我們這邊仍然是先根據 p-value 區別關鍵字的顯著性
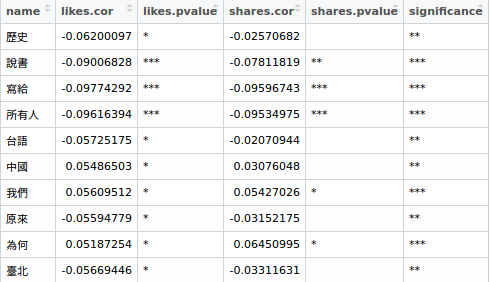
p.value >= 0.05:不顯著0.01 <= p.value < 0.05:稍微顯著,我們以*標記0.001 <= p.value < 0.01:顯著,我們以**標記p.value < 0.001:非常顯著,我們以***標記
透過這些作法與標記,我們可以個別得到單字跟按讚的關聯性與顯著程度,以及單字跟分享的關聯性與顯著程度,我這邊為了最後要輸出的二維圖,還額外加了一個欄位 significance 代表單字同時對按讚與分享顯著,只對其中一項顯著,或是對兩者都不顯著的標記
6. 資料視覺化
我在這邊使用的是 R 的 ggplot2,這是一個非常強大也非常具有彈性的繪圖函式庫,我在 reference 中也列了一些可以參考的網站,所以這邊我就不多做介紹了
做到最後一步,發現單字太多會造成圖表混亂,所以我這邊會手動挑出比較極端的關鍵字,然後不顯著的我後來也乾脆就不列出來了,因此最後的結果比較會像是以下這種圖
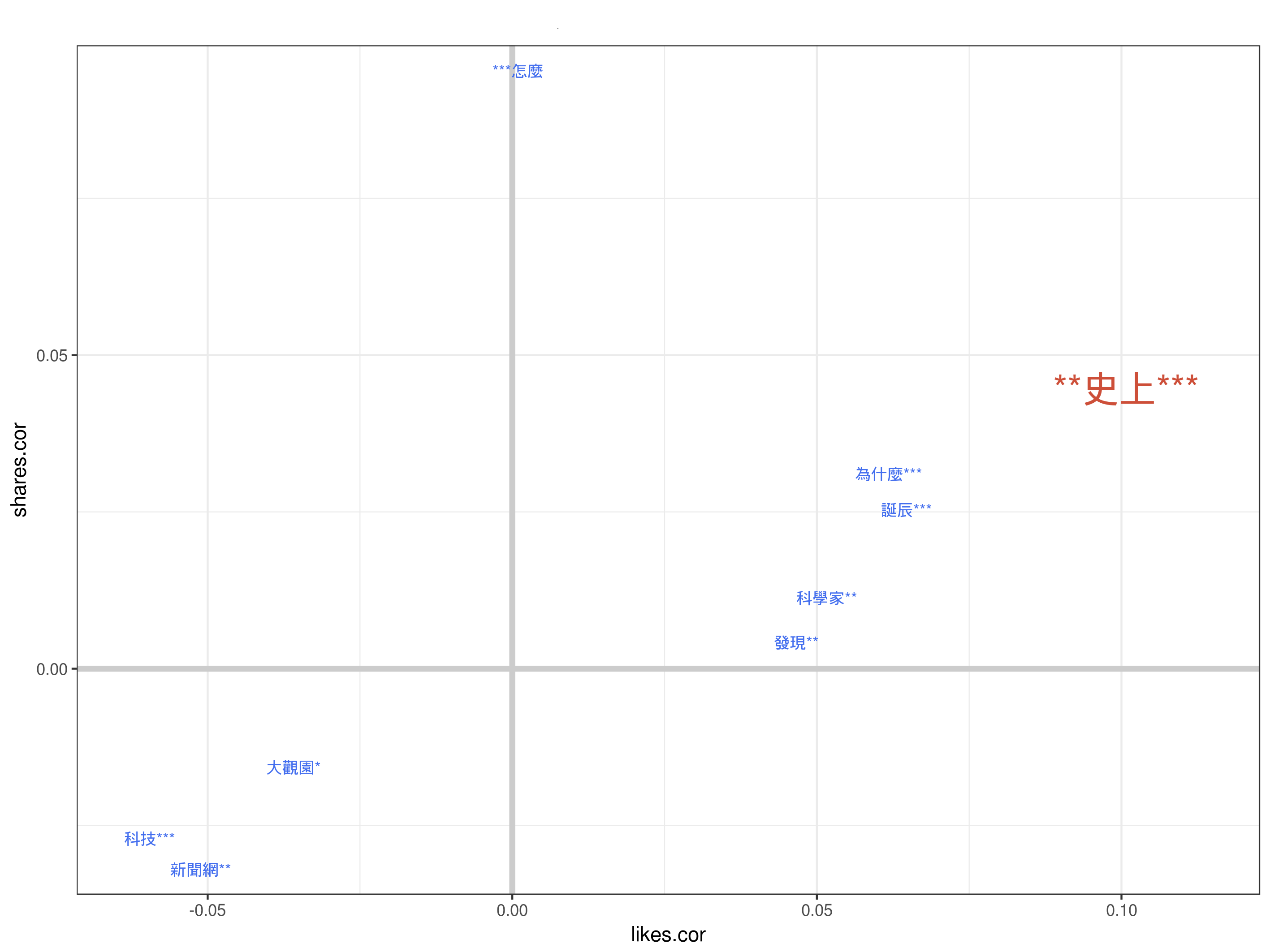
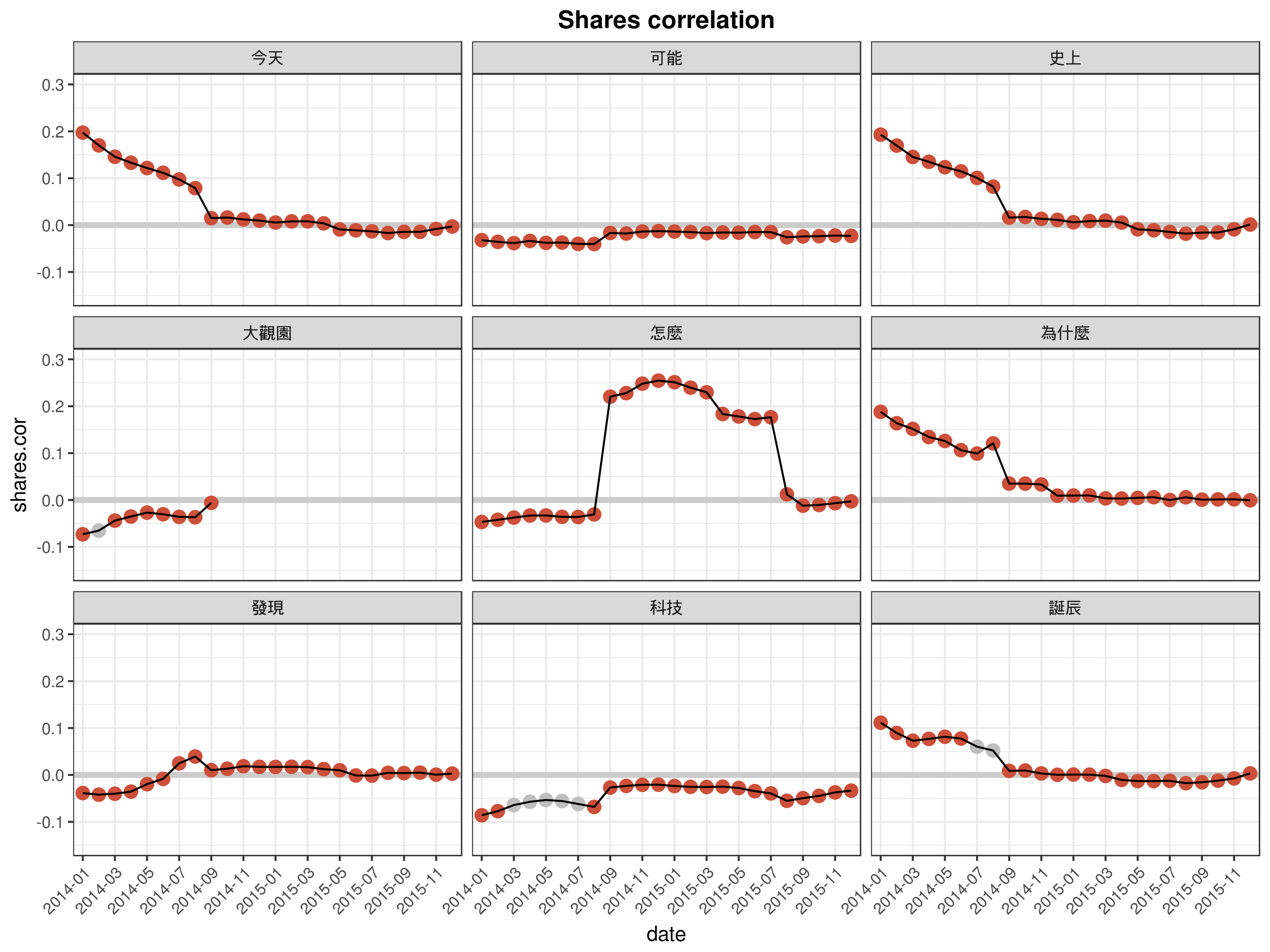
當然這是比較一般性的分析,同樣的一份資料我們還可以根據日期看趨勢,以一個月為位移單位,一年份為資料集大小,透過 facet_wrap 可以做出以下這種圖表
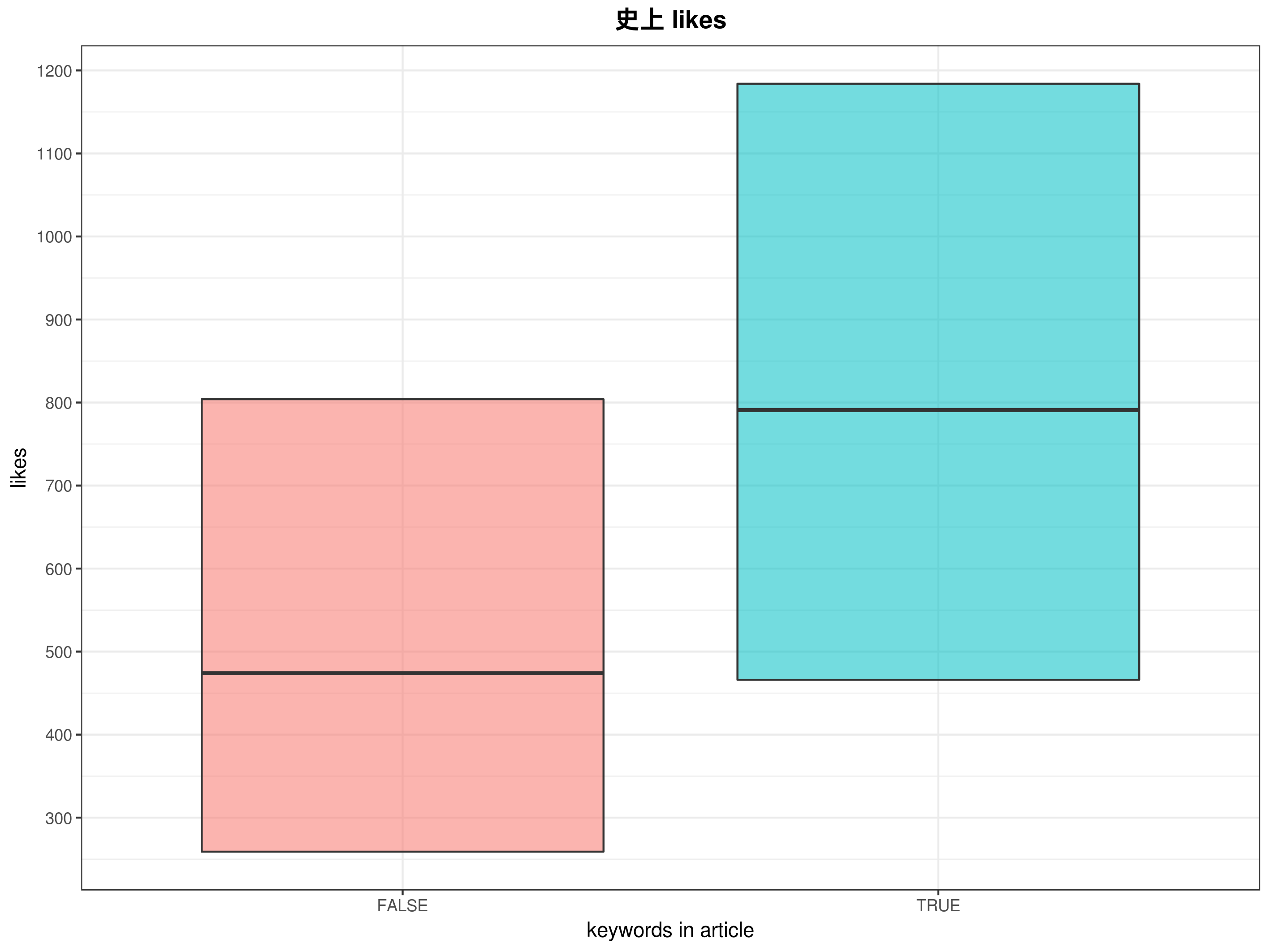
又或者有特別需要提出來做範例與介紹的關鍵字,我希望知道他在文章中與按讚或是分享數的分佈狀況,可以透過 boxplot 來做,如果要一次呈現二維資料可以參考 stat_ellipse
結語
以上列的是在兩個禮拜內從毫無經驗,歷經爬蟲,分析到視覺化的過程,其實這些都只是算是很基礎的資料分析過程,如果有人有看過陳昇瑋老師的報告可能會覺得很多圖表都很像,那是因為我就是直接問那些團隊裏面的人邊學習的,哈哈哈
看完那份報告,其實可以知道我這些只是很初期的分析程度,甚至也還不夠完美,但是對我來說卻是一個很好的練手,如果未來我開始接觸後面那些包含模型的建立,機器學習的部份,我再繼續分享
如果對我這篇文章有任何指正的也歡迎一起討論