

前言
這篇文章是紀錄我第一個爬蟲任務的 writeup。在之前我只能說自己對爬蟲有點概念,但開始做這個比較 general crawling 的任務之後,對於學習爬蟲的過程有了一點脈絡。這次被要求的爬蟲內容為取得上千個網站中的所有圖片、影片與文件,但為了減少我們儲存資料的容量,我們設計成圖片與影片只抓取其來源,而文件因功能需求抓取完整檔案。
從網頁到網站
Python 新手剛學習爬蟲時,網路上一堆教學都會教你如何透過最基本的 requests 與 BeautifulSoup4 爬取網頁。基本的流程是透過 requests 送 HTTP 請求到目標網站主機,取得頁面的 HTML 檔案後再透過 BeautifulSoup4 分析之,經由這兩個簡單步驟,我們基本上可以拿到我們想要的資料。
從單一網頁爬蟲到網站爬蟲,通常只是簡單的判斷 following link,也就是透過 BeautifulSoup4 分析出 <a href="..."> 之後再重新對 href 中的新 URL 送 HTTP 請求,看起來很簡單,但卻有幾個問題必須特別注意,以下說明之。
Domain 的判斷
通常在對 href 屬性的值送請求之前,我們都會透過 urllib.parse.urljoin 等方式將相對路徑轉成絕對路徑,接著再對絕對路徑送出請求。但在送出之前,如果沒有考慮到 domain 問題,很有可能會把大半個網路的內容全部都抓回來,尤其像這種爬多個網站的任務,其沒有非常明確的爬蟲目標,如果某個網站在你沒有注意到的地方把一些大型網站的網址附上,如 google.com、facebook.com、youtube.com⋯⋯等。
要判斷這種完全不同的網域,我們可以簡單的透過 urllib.parse.urlparse 將 URL 的格式 parse 出來,透過 source code 你可以觀察到他解析出來的格式是 <scheme>://<netloc>/<path>;<params>?<query>#<fragment>,透過其中的 netloc 就可以知道是否為相同的網域。
但是上面這種判斷方式會將子網域的網站排除在外,舉例來說,學校的網站與各系所的網站(如:台大首頁的網址是 www.ntu.edu.tw,台大中文系的網址是 www.cl.ntu.edu.tw)透過 urlparse.parse.urlparse 的 netloc 你會判斷 "www.ntu.ed.tw" != "www.cl.ntd.edu.tw"。
如果子網域的網站也在你的爬蟲目標內,我們可以透過另外一個 tldextract 來當 urlparser。tldextract 會維護一份頂級域名的字典,所以可以透過 tldextract.extract 將 URL 拆解並回傳 ExtractResult 物件(source code),可以透過存取 ExtractResult 物件取得拆解後的 URL 片段,包含 subdomain、domain 與 suffix,基本上可以視為 neloc = subdomain.domain.suffix。
HTML5 structure v.s. non-HTML5 structure
原本以為圖片只要分析 <img> 元素,影片只要分析 <video> 元素,文件只要分析 <object> 元素,但是後來才發現這一切都太異想天開,網路中還是有大部分的網站,使用的是以前 IE 時代的寫法,所以要判斷的元素變得非常的多。
對此,我們決定採用正向原則,也就是我們有定義的元素才爬,下面列出我後來實際上有爬的:
<img src="..."><video src="..."><object data="..."><picture srcset="..."><source src="..."><source src="...">
然後有判斷 following link 的元素為:
<embed src="..."><iframe src="..."><frame src="..."><a htef="...">
過濾 href
透過分析元素取得的資料來源,有可能是 internal file,也有可能是 external file。影音如果是 YouTube 之類的影音串流平台,雖然 domain 不同,但其實也只需要獲取資料來源就好;至於 internal file,其路徑有可能是相對路徑或是絕對路徑,建議透過 urllib.parse.urljoin 統一轉成 URL 再做處理。
另外,處理 <a href="..."> 時,資料來源有可能會包含錨點 # 或是 JavaScript code,要記得排除這些 pattern。
動態網頁
動態網頁,換句話說,就是經過程式碼改變網頁內容的網頁,但是透過 requests 送出請求所拿回來的 HTML 會是靜態網頁,也就是打開瀏覽器透過 「檢視網頁原始碼」 看到的內容,但我們通常希望 「What the user sees, what the crawler sees.」,也就是希望爬蟲拿到的內容是透過瀏覽器的 「開發者工具」 看到的內容,為了這個目的,目前被廣為使用的工具是 Selenium。
Selenium 其實是用來做網頁自動化測試的工具,可以模擬使用者操作瀏覽器的行為;額外安裝 driver 就可以操作我們一般在使用的瀏覽器,可以透過程式操作 Chrome 或是 Firefox 等瀏覽器檢視網頁操作是否正確。也因為它可以模擬瀏覽器行為,所以他也就有能力拿到 JavaScript render 之後的 HTML(通常稱之為 HTML Snapshot)。
因為 Selenium 是透過程式操作瀏覽器行為,所以比起靜態爬蟲速度會比較慢. 雖然有另外一個 driver PhantomJS 是沒有圖形化介面的,速度上來說會比 Chrome、Firefox 等 driver 還要快,但這邊可以的話,還是先嘗試攔截 AJAX 直接爬蟲會更快。
加速爬蟲
回頭檢視爬蟲需求,我們的目標是上千個網站,一個一個慢慢爬的時間成本太高,且往後如果要做定期更新的話,根本不是一個實際可用的程式,以下會從各個層面來討論爬蟲效率。
HTML parser
BeautifulSoup 以前也是因為速度太慢所以被捨棄,目前速度最快的 HTML parser 是 lxml,而 BeautifulSoup4 出來之後可以選擇背後實作的 parser,這邊建議選擇 lxml。
requests timeout
雖然說減少 request timeout 的時間長度也可以變相加速,但個人不太建議這麼做,單純縮短timeout 的時間,也就代表你送請求的頻率變高,如此目標網站的 loading 會上升,一來有可能癱瘓對方,二來有可能一下子就被認為是 crawler 然後被 ban。
async or multithreading
雖然 Python 因為 GIL 的關係所以 multithreading 的實作效果不怎麼好,但還是比不做更好。但因為送請求這種任務,大多時候是在網路等待中空轉,所以比起 multithreading 其實使用 async 更好。
更新流程
考慮到往後,我們希望手上的資料盡可能的是最新資料,所以程式會放入 crontab 中做定期爬蟲的排程,這個時候針對下載檔案這件事情,我們應該先判斷該文件是否有更新。
參考 Google Web Developer 文章,比起考慮 response header 中的 Last-modified,不如考慮 ETag 更適合,又因為我們在下載之前需要的,僅僅只是檢查文件是否有更改,所以比起送 HTTP GET/POST,送 HEAD 其實就夠了,相較之下可以減少更多頻寬。
p.s. 這邊其實我覺得這種作法並不是很好,如果有大大覺得有更好的作法,再麻煩聯絡我,像是再這種任務底下實作 notify 架構。
toolkit v.s. project
如果只是一次性的爬蟲,上面那些考慮完基本上就差不多了,但是討論到更新流程時,這是一個要持續使用的程式,workflow 必須定義的更明確,而且還有一個沒被討論到的問題:「要透過甚麼方式防止 IP 被網站 banned?」
IP 被 banned 這件事情其實有很多種處理方法:
- 動態改變 User-Agents
- 不要使用 cookies
- download delay
- Google cache
- VPN、Proxy、tor
- 分散式爬蟲
不過,我後來把上面那些東西全部放棄,然後引入 Scrapy。
Scrapy 是一個爬蟲框架,workflow 也非常完善,送 request 跟 download 的部份以 Async 實作,因此爬蟲流程的速度還可以再稍微加快一點,只是我們剛剛上面提的東西可能都要換另外一種實作方式。
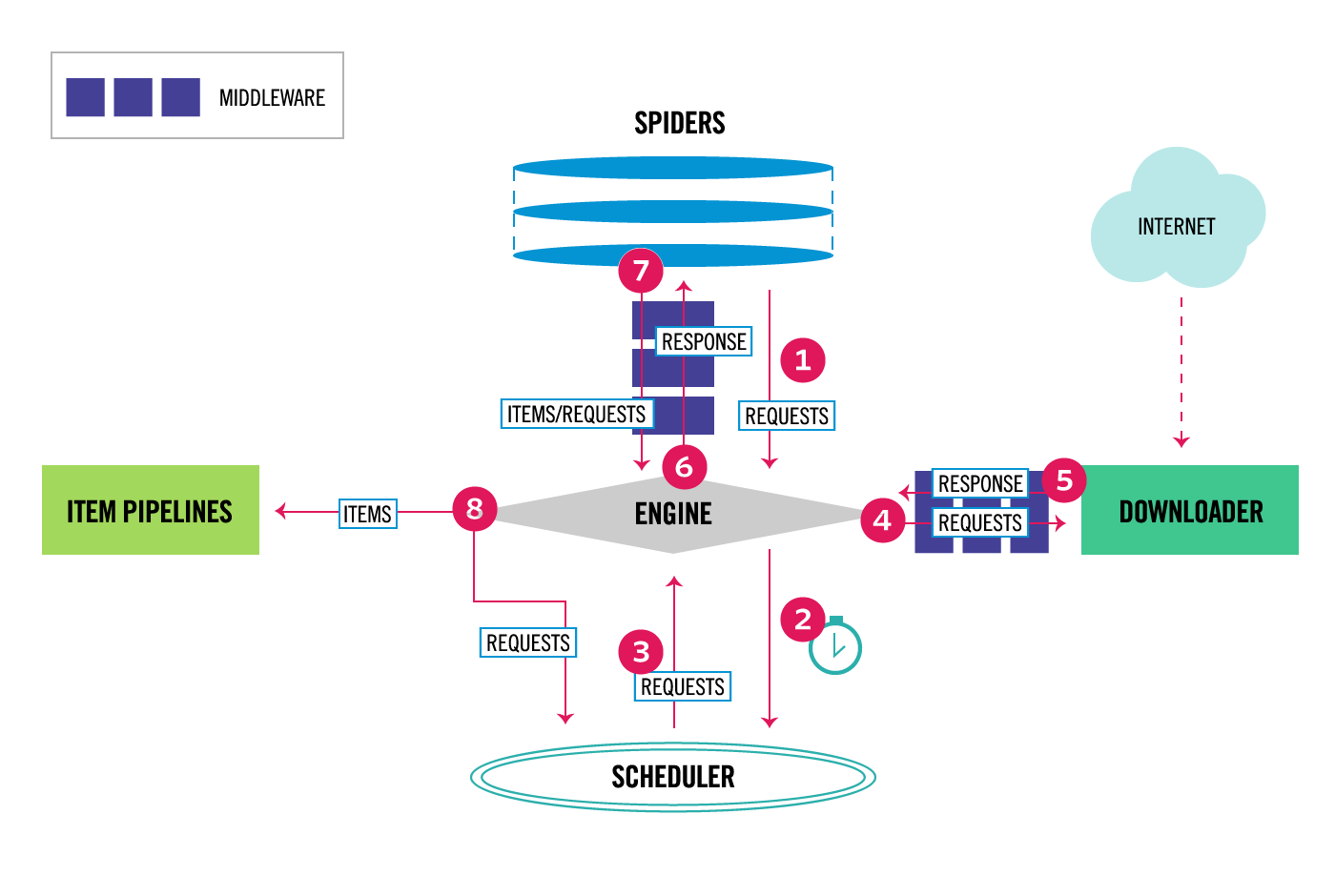
我們導入框架之後主要的任務是寫一個 spider,他的工作內容就是爬蟲,基本上只要把送 request 跟 parse HTML 的邏輯搬過來以 class 的方式實作就可以,而我們原本要紀錄與下載檔案的部份,則是到 item pipeline 處理,其他功能的替換如下:
- 動態渲染網頁:
Selenium→scrapy-splash - HTTP cache & Etag validation:設定 downloader 採用 RFC2626 policy
除此之外,downloader 這邊我們可以根據需求再增加其他 middleware,像是上面提到的更改 user agent、建立 IP pool 來防止 IP 被 banned,還有檢查同樣的 URL 是否已經送過 request。
不過 multiprocessing 的解法呢?
StackOverflow 上面有人解釋,Scrapy 本身是建立在 Twisted 這個 Event-driven networking engine 的基礎之上,他本身就有處理 Async 的方式,如果在 Scrapy 中使用 multiprocessing 可能會有無法預知的錯誤,比較好的作法是參考 Run Scrapy with Scrapy 的方式額外寫一支 script,把剛剛寫的 Scrapy spider 引入再實作。
雖然可以透過撰寫 Twisted 使用 spawnprocess 達到 multiprocessing 的功用,不過若是專案中沒有需要處理 spider 以外的操作,scrapy 也提供了 scrapy.crawler.CrawlerProcess 這個 API 讓開發者可以更方便使用。
後記
這其實是我第一次接觸的爬蟲專案,也算是因此一次性的接觸了很多工具,上面這些也只是討論一些很基本擋 bot 的方法,而且後面紀錄 record 之後我也沒有紀錄直接存入資料庫的方式。
但也算是對於整個瀏覽器的操作跟網路送 request 的流程有更進一步的認識,整個從頭到尾大概花了我一個月 pick up + implementation,但是是很有趣而且門檻不會太高的一次實作。
- 然後這邊有後來開課的投影片與 slideshare,可能會不定期更新,歡迎各位大大指教。